


Problem
The Solana Community Dataset is a public good freely accessible to all Google Cloud users, with costs determined solely by the volume of data scanned.
However, the original architecture — designed before BigQuery’s modern partitioning capabilities — inadvertently imposed a meaningful cost barrier. Without granular partitions, simple queries often triggered full-history scans, driving expenses into the thousands. This modernization resolves that structural inefficiency, aligning query costs with the actual scope of analysis.
Solution
The BCW engineering team resolved significant performance bottlenecks in the Solana Community Dataset through a comprehensive architectural overhaul. This effort focused on three key technical interventions to optimize data retrieval:
- Re-partitioning: Logically dividing large data tables into smaller, manageable segments to reduce scan size.
- Re-clustering: Physically organizing related data together on disk to minimize I/O and speed up access.
- Mandatory WHERE Clause: Enforcing a required filter (e.g., a date range) on all queries for the largest tables. This critical step prevented resource-intensive full-table scans.
This three-pronged approach successfully enhanced query efficiency, making the dataset significantly more usable and efficient for all stakeholders.
Outcome
As a result, the minimal data range for queries was reduced from a month to just one day, yielding a significant improvement in query cost of more than 10 times. Furthermore, including one or several of the clustering parameters in the SQL query can further optimize the request and lower the cost for the end users.
Key advantages of the shift to smaller, more granular daily blocks include:
- Faster Query Execution: Less data scanned means reduced I/O and processing time.
- Substantially Lower Costs: Minimizing scanned data volume significantly lowers costs in usage-based cloud data warehousing.
- Enhanced Efficiency and Reliability: The more efficient retrieval process improves system stability, especially under heavy load.
A compelling example illustrating cost optimization is the comparison of the query before and after implementation:
Before, to query all data per a single block, the query processed a month of data. The query would have processed ~3.58TB of data, which would cost ~$90 (USD).

After, to query the same information within the updated dataset configuration will process over 10 times less data and will cost ~$7 (USD).

Further use cases for the updated Solana Community Dataset are detailed in this blog post.
Case Study: Technical Deep-dive
How We Solved It: Engineering at Petabyte Scale
To address the challenge of making Solana’s massive dataset — over 1 petabyte (1,000 TB) of historical data — cost-effective and performant for users, we needed to fundamentally restructure how the data was stored in BigQuery.
Our goal was to move from coarse-grained storage to a highly optimized schema featuring granular partitioning and targeted clustering. However, modifying a dataset of this magnitude is not as simple as running a standard SQL update. It required a specific engineering strategy to bypass the resource limits of standard BigQuery operations.
1. The Foundation: A Scalable Ingestion Framework
Before optimizing the storage, we leveraged our Open Source Rust-based ETL framework. By utilizing this high-performance architecture, we ensured that the massive influx of Solana data (transactions, instructions, and blocks) could be ingested with safety and reliability, laying the groundwork for the storage optimization.
2. The Challenge: Hitting the “Petabyte Wall”
Our objective was to re-partition the dataset and apply clustering to high-traffic columns to drastically reduce query costs.
The Failure Mode: We initially attempted a standard “Create Table As Select” (CTAS) query to back up and restructure the data. This approach immediately failed. We discovered that at 1PB scale, the sheer volume of data exceeded the memory and processing limits for a single BigQuery job. We could not simply “query” our way out of the problem.
3. The Solution: A Two-Step “Hardware-Level” Migration
To overcome these size constraints, we devised a two-step migration strategy utilizing specific Google Cloud tools designed for heavy data lifting.
The migration process diagram:
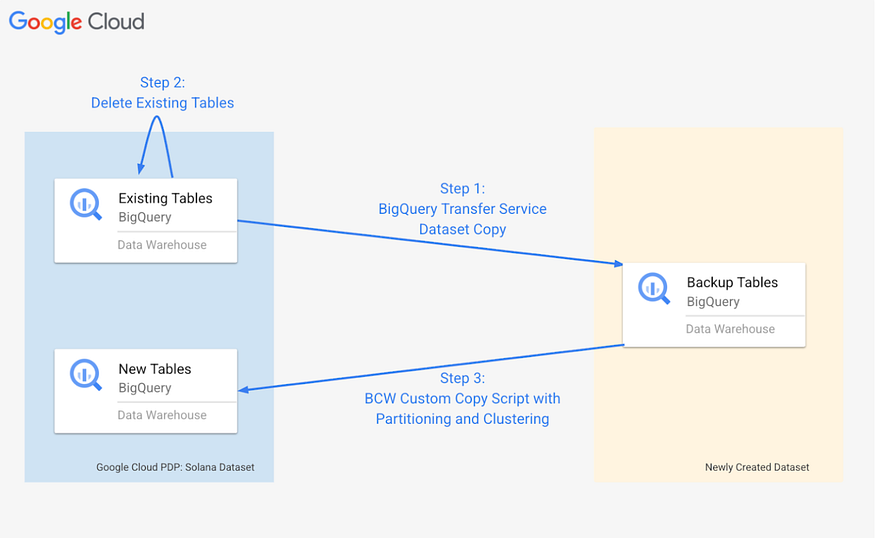
The implementation involved three key steps to successfully migrate and optimize the public dataset:
- Step 1: Backup via BigQuery Transfer Service Since standard queries failed to create a backup, we switched to the BigQuery Transfer Service. By specifically utilizing the “Copy Dataset” configuration, we were able to offload the heavy lifting to Google’s background transfer infrastructure. This allowed us to successfully create a complete, isolated backup of the public dataset without hitting query resource limits.
- Step 2: The existing tables were deleted as they were not required for the subsequent steps.
- Step 3: The “Clustering” Strategy (Iterative Restructuring) BigQuery does not allow modifying the partitioning specification of an existing table directly. We had to reload the data into new, optimized tables.
- Attempting to copy the backed-up data back into the new schema in one massive operation also hit resource limits. To solve this, we developed a custom migration script. This script programmatically iterated through the backup month-by-month, inserting data into the new partitioned and clustered tables in manageable chunks. This “divide and conquer” approach allowed us to process the full history flawlessly where a single query had failed.
Script to recreate the table with the new schema, including partitioning and clustering (Transactions example):

Script to copy over the data by each partition/month (Transactions example):

4. The Outcome: Optimized Performance & Cost Control
Internet Capital Markets demand data infrastructure that matches the chain’s velocity. By upgrading from monthly to daily partitions, we’ve aligned the dataset with market microstructure — enabling analysts to isolate queries with high precision.
- Targeted Clustering: Users filtering by specific high-cardinality attributes (such as transaction signatures or account keys) now scan only a fraction of the data.
- Granular Partitioning: Data is efficiently organized by time, allowing for precise historical queries.
- Resilience: The successful backfill proved that our “clustering” management strategy can handle future maintenance on petabyte-scale datasets without downtime.





